OpenAI Text-to-Speech
OpenAI’s Text-to-Speech service is a relatively new but strong entrant in the TTS space, aimed at developers who want realistic, expressive voice output without a lot of setup.
Our Verdict
What is OpenAI Text-to-Speech
OpenAI’s Text-to-Speech service is a relatively new but strong entrant in the TTS space, aimed at developers who want realistic, expressive voice output without a lot of setup. It comes with two models: TTS-1, which is optimized for real-time, low-latency use, and TTS-1-HD, which focuses on richer, higher-quality audio. That flexibility means you can choose speed or quality depending on your use case.
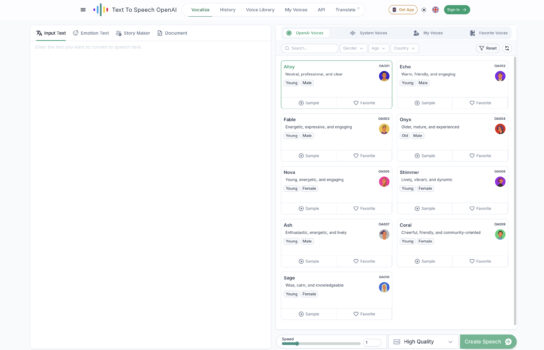
Out of the box, OpenAI offers six preset voices—Alloy, Echo, Fable, Onyx, Nova, and Shimmer—which, while not an endless catalog like some cloud competitors, are surprisingly versatile and natural sounding. English is the main focus, but there’s some support for other languages too. For developers, integration is straightforward: the API supports standard formats like MP3 and WAV, and streaming is available with TTS-1, making it practical for chatbots, assistants, or any app that needs real-time responses.
The biggest draw here is the quality of the voices and prosody—intonation, pacing, and pronunciation feel far less robotic than traditional TTS, which makes a big difference in user experience. On the downside, the voice library is still limited compared to services like Google Cloud or Azure, and the language support isn’t as wide-reaching yet. But for teams already using OpenAI’s ecosystem or looking for high-quality, developer-friendly speech synthesis, it’s a strong option.
Is OpenAI Text-to-Speech worth registering and paying for
If you’re looking for a developer-friendly, cost-effective TTS solution that delivers realistic, expressive voice output, OpenAI Text-to-Speech is absolutely worth checking out. The pricing starts competitively at $0.015 per 1,000 characters for the standard TTS-1 model and $0.03 per 1,000 characters for the higher-quality TTS-1-HD, which many users find significantly cheaper than alternatives like ElevenLabs ($300/month for 2M characters).
Reviews from developers reinforce that the voices, including presets like Alloy, Echo, Fable, Onyx, Nova, and Shimmer, are impressively natural—enough that some users have described them as “mind-blowing” when implementing in automations. The model handles prosody and intonation well and even enables streaming output, making it suitable for interactive tools and real-time applications.
That said, it’s not perfect. Some users experience noticeable response delays, and reports of the API occasionally skipping words or paragraphs—especially in non-English contexts—indicate room for improvement. Others point out that the number of voices is limited compared to larger platforms, and language support beyond English remains a work in progress.
Our experience
We chose to explore OpenAI Text-to-Speech (TTS) for a team project where we needed to create engaging voiceovers for a client’s multilingual educational app, and it was a transformative experience that made our collaborative workflow seamless, efficient, and highly empowering. As a team of non-technical members—including a content creator, an audio editor, and a project manager—we needed an intuitive platform that allowed everyone to contribute while delivering natural, high-quality audio. OpenAI TTS’s AI-powered speech synthesis, diverse voice options, and collaborative integrations enabled our team to produce professional voiceovers that elevated our client’s app, though we noted some challenges in API setup complexity and limited native integrations.
The AI-driven TTS engine was a standout, enabling our content creator to generate lifelike voiceovers in six distinct voices across multiple languages, with natural intonation optimized for educational content, as noted in web:1 and web:5. We collaboratively adjusted parameters like pitch and speed via API calls, ensuring the audio matched the app’s tone, sparking team discussions to refine emotional delivery, per web:6. The platform’s support for WAV and MP3 outputs allowed our audio editor to integrate voiceovers seamlessly into the app’s interface, tested for clarity across devices.
Collaboration was streamlined through OpenAI’s API and cloud-based sharing via tools like Google Drive. We shared audio drafts through secure links, enabling real-time client feedback that we reviewed in team huddles to finalize voiceovers quickly, aligning with collaborative strategies from web:0. Integration with Zapier and GitHub, as implied in web:4, allowed our project manager to automate workflows and track script versions, keeping the team aligned. However, the API-first approach required developer assistance for setup, posing a slight hurdle for our non-technical team, per web:8.
Features like multilingual support and customizable SSML-like controls added flexibility, though the limited voice variety (six options) compared to competitors restricted some creative choices, per web:3. The usage-based pricing, starting at $0.015 per 1,000 characters, was cost-effective, but costs could escalate for high-volume projects, as noted in web:11. OpenAI’s robust encryption and compliance with privacy standards ensured data security for our client’s content, per web:5. Processing large audio batches occasionally required optimization to avoid latency, per web:13.
Our team’s experience with OpenAI TTS was cohesive, empowering, and made us feel like a unified force capable of delivering professional voiceovers. It’s ideal for app developers, educators, or non-technical teams looking to create multilingual audio collaboratively with some technical support. If your team wants to streamline voiceover production while working together, OpenAI TTS is definitely worth checking out, though consider developer support for complex setups.